안녕하세요
본 강의(포스팅)은 아래의 사이트 내용을 일부 번역하고 필자의 의견을 추가 구성한 글임을 미리 밝혀드립니다.
https://www.analyticsvidhya.com/blog/2015/11/improve-model-performance-cross-validation-in-python-r/
데이터 해카톤(Data Hackathons)를 종종 모니터 하다보면 흥미로운 점들이 발견됩니다.
그 흥미로운 점은 해카톤의 성적 순위를 공개되어 있는 것을 보면 PUBLIC LEADER BOARD 순위와
PRIVATE LEADER BOARD순위 로 나누어 져있는 것을 볼수 있습니다.
(이것은 단체 순위 , 개인순위로 해석되기보다는 공개용 데이터로 분석하고 내놓은 모델의 정확도 순위와
그 동일한 모델을 가지고 비공개적으로 다른 데이터를 여러게 적용해보고 난 이후에 매긴 정확도 순위로
해석하는게 좋을듯 싶습니다.)
PUBLIC LEADER BOARD 순위 에서 상위에 올라있는 참가자는 순위표가 PRIVATE LEADER BOARD순위 에서
유효성을 확인한 후 공개용 순위에서 많이 떨어져 있는 경우도 있었고,일부는 TOP 10안에 들어감에도 불구하고
PRIVATE LEADER BOARD순위 에서 (아래 이미지)에서 상위 20 위도 차지하지 못했습니다.
왜 이러한 현상이 발생하는 것일까요?
왜 이러한 순위의 큰 변동이 일어나는 이유는 무엇일까요?
즉 주어진 공개용 데이터를 바탕으로 만들어진 모델링 알고리즘이 왜 다른 데이터를 기반으로 모델을 평가할경우
그 모델의 안정성이 저하되는 이유는 무엇일까요?
맞춰보세요! 랭크의 높은 변동에 대한 가능한 이유는 무엇일까요? 즉, 개인 리더에서 평가할 때 모델의 안정성이
저하되는 이유는 무엇입니까? 가능한 이유를 살펴 보겠습니다.
왜 모델의 안정성(Stability)이 줄어들었을까요?
아래의 그림을 바탕으로 이해해 보도록 해보겠습니다.
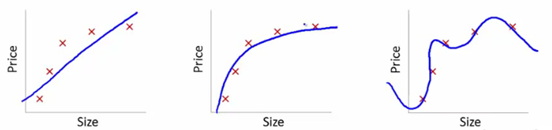
여기에 사이즈와 가격간의 상관관계를 찾는 그래프가 여러가지 있습니다.
주어진 데이터를 기반으로 관계 그래프를 위와같이 만들었고 주어진 데이터들은 5개의 점으로 표현하였습니다. 첫번째 그래프는 주어진 5개의 학습데이터 포인트(training data point)에 높은 error를 가지고 있지만 모델은 곧은 선형으로 표현했습니다. 이 모델은 높은 에러를 가지고 있으므로 예측이 정확하지 않아서 public 과 private leader board에서 높은 순위를 가지고 올수 없을것입니다. 이렇게 높은 error를 가지고 있는 fitting을 "under fitting"이라고 합니다. 이 모델은 데이터의 트렌드를 이해하는데 부적절하다고 볼수 있습니다.
두번째 그래프는 size와 가격의 데이터 포인트를 잘 표현하였고, 그 추세를 잘 표현한 모델이라고 할수 있습니다. 낮은 학습 에러(trainning error)를 포함하였고, 가격과 사이즈에 대한 관계를 일반화(generalization of relationship) 했다고 이야기 할수 있습니다.
세번째 그래프는 거의 영에 가까운 학습 에러를 가진 모델입니다.(relationship which has almost zero training error). 즉 주어진 5개의 데이터 포인트로 완벽에 가까운 관계식을 만들었고, 5개의 데이터 포인트로 비교해 봤을 때 size를 입력했을 때 그 관계식에서 발생하는 값과 실제값의 차이(즉 오류 error)는 0에 가깝다고 할수 있을 정도로 복잡한 모델을 만들었다고 보면 됩니다.
복잡한 모델 즉 관계식은 "Over fitting"되었다고 표현하고, 보통 이런 경우에 public learder board 와 private learder board에 큰 차이를 발생시킵니다. 즉 정확한것처럼 보이지만 그 모델(관계식)이 표현하고자 하는 size와 price의 관계가 너무 민감하게 표현되어서 , 실제 눈으로 예측하는 관계와는 큰 차이가 발생하게 되는 것입니다
데이터 과학 경진 대회의 일반적인 목적은 다양한 모델을 반복하여 더 나은 성능 모델을 찾는 것입니다.
그러나 관계식을 주어진 데이터로만 만들다보면 우리가 관계를 더 잘 포착했거나 주어진 데이터에만 모델을 지나치게 잘 맞추고 있기 때문에 주어진 데이터로만 성능가 향상되는지 여부를 구별하기가 어려워집니다.그렇다고 여기에 새로운 데이터를 학습시켜볼수는 또 없는 노릇입니다. 따라서 주이진 데이터를 가지고 좀더 과학적인 교차 검증 기술이 필요합니다. 이 방법만 있다면 주어진 데이터만으로 일반화를 시키고 이것이 객관적으로 사람들에게 말할수 있는 size와 price간의 관계라고 이야기 할수 있다고 하는 것이죠.
그렇다면 교차 검증 혹은 교차 유효성 검사(cross validation)은 어떻게 하는 것일까요?
Cross Validation 은 주어진 데이터를 일부 나누어서 한 쪽 데이터로는 학습을 시켜 모델를 만들고
(모델을 만든다는 의미는 x와 y의 관계식을 추정한다고 이해하시면 됩니다.)
나머지 학습시키지 않은 데이터로 그 모델에 대해서 검증하는 방법을 말합니다.
방법은 아래와 같습니다.
1. 예를 들어 100개의 데이터 set이 있다고 하고, 70개는 학습을 시키는 데이터 즉 train data set,
30개는 검증하는 데이터 즉 test data set 혹은 validation data set으로 지정해놓습니다.
2. train data set을 가지고 모델링을 하여 모델을 만듭니다.
3. 만든 모델을 test data set으로 모델을 평가합니다.
4. train data set과 test data set을 통해 얻은 error를 그래프를 그려보고 그 그래프가 만나는 최적의 점을 찾아 최적화 합니다.
Cross validataion의 종류 및 각각의 방법들
cross valiation 은 예를 들어 설명하긴 하였지만, 꼭 70 : 30으로 만 나눌 필요는 없고,
또한 두개의 그룹으로만 나눌 필요는 없습니다.
나누는 비율과 그룹에 따라서 여러가지 종류의 cross validation이 존재하며
대표적인 방법들은 아래와 같이 설명합니다.
1. The validation set Approach
이방법은 50%의 data 는 검증을 위해 남기고, 다른 50%는 모델 학습을 위해서 남겨놓습니다.
모델 학습후 모델 검증은 validation data를 가지고 합니다.
(보통은 50:50도 많이 하지만 70:30 도 하는경우도 있고
둘다 the validation set approach라고 이야기 할수 있습니다.)
이 방법의 단점은
1. 일부의 데이터만 학습을 하기 때문에 모델이 일부 데이터를 설명하기에는
부족하지 않겠지만 경우에 따라 전체 데이터를 설명하는데는 부족한 모델이 될수 있습니다.
이것을 통계적 용어로 "bias 가 높다"고 할수 있는데 , 경우에 따라 일부 데이터로만 학습하였기 때문에
모델이 bias가 높은 경우가 될 가능성이 높습니다
즉 한국인의 한달 소득과 소비 값의 관계식을 파악하고자 모델을 만들었는데,
하필 학습시킨 데이터는 30대 이상이고, 검증하는 데이터는 30대 이하일 경우,
30대 이상의 데이터로 만 학습하게 되면 전체 소득과 소비 값에 대비해서
편중된 모델이 만들어질수 있습니다. 즉 편중된 모델이라는 것은 높은 bias 나타난다라고 이야기 할수 있고,
이것은 전체를 설명하는데 부적절해 지게 됩니다.
2. Leave one out cross validation (LOOCV)
이 방법은 하나의 데이터 포인트만 남기고 나머지 모든 데이터로 학습을 시켜 모델을 만드는 것입니다.
그리고 다시 다른 하나의 데이터 포인트만 남기고 나머지 모든 데이터로 학습을 시킨 후 여러번 반복해서
남겨둔 포인트들로 검증을 하는 방법입니다.
이렇게 될경우에는 몇가지 장점과 단점이 발생하는데
장점 : 거의 모든 데이터로 모델링해서 bias가 적다
단점 : 1. n번 반복시행할 경우 n배 만큼 실행시간이 길어진다.
2. 이 방법은 모델검증에서 여러가지 다양한 결과가(즉, 높은 분산이) 발생 시킬수 있습니다.
다시 말해서 검증을 위해서 제외시킨 하나의 data point가 예측의 큰 영향을 미치기 때문에,
그 검증 데이터가 outlier였다면 모델은 최적의 모델이었으나, 검증 결과는 최악의 모델이 될수도 있고,
모델은 최악의 모델이었으나 검증 결과는 최적의 모델로 검증될수도 있습니다.
3. k-fold cross validation
위의 두가지 방법을 통해서 우리는 아래와 같은 사항을 배울수 있었습니다.
1. 우리는 data set에서 많은 부분의 데이터로 모델을 학습시켜야 합니다 .
그렇지 않으면 높은 bias를 가진 모델을 얻게됩니다.
(즉 한국인의 소득과 지출관계에서 40대 이상의 모델을 얻고
이것이 한국인을 대표한다고 말해야하는 경우가 high bias라고 할수 있습니다)
2. 우리는 최적의 비율로 test data set을 나누어야 합니다
적은 수의 데이터로 test 를 할 경우 모델의 효율성을 평가할때 높은 분산을 얻게 됩니다.
(즉 효율성이 좋다고 나와야 함에도 적은 데이터로 인해 검증할때는
효율성이 낮게 나올수 있다는 것입니다.그리고 이것을 10번할때
이러한 오차가 빈번하게 발생하면 높은 분산을 얻었다고 표현할수 있습니다.)
3. 우리는 학습과 test(검증)을 여러번 시행하되, 학습과 검증의 분포를 다르게 해서 여러번 시행해야 합니다.
이것이 검증에 큰도움을 줍니다.
그렇다면 세가지 요건에 맞는 방법은 무엇일까요
그것은 “k- fold cross validation” 입니다.
그것의 세부 방법은 아래와 같습니다.
1. 무작위로 데이터를 k개의 fold (겹, ex> 여러겹) 로 나눕니다. 즉 100개를 k 개의 집단으로 무작위로 나눕니다.
2. 각 집단 중 하나의 집단이 test set이 되고 나머지는 학습을 위한 데이터로 진행합니다.
3. 학습한 모델을 기준으로 test set으로 평가한 error를 기록합니다.
4. 이것을 돌아가면서 k번 실시합니다.
5. 기록한 error를 평균을 내고 그것을 cross-validation error라고 칭하고, 모델을 평가하는 하나의 지표로 활용합니다.
아래는 k가 10이라고 하고 , 10개의 군집을 나누어서 training하고 validation을 한 것을 표현한 것입니다.

그럼 좋은 결과를 얻기 위해서는 k를 몇으로 지정하여야 하까요?
정해진 것은 없지만, 보통 10개를 하고, 필요에 따라서 더 많이 합니다.
명심해야할 것은 K가 적어질수록 모델의 평가는 편중될수 밖에 없으며, 결과도 정확하지 않습니다.
k가 높을수록 평가는 bias가 낮아지지만, 결과의 분산이 높을수 있습니다.
(즉 k=100일 경우 정확도가 1~100점이라고 나올수 있으며, 이럴경우에는
50점의 정확도를 가진다고 표현할수 있으며,
k=20일 경우 정확도가 25~75점이라고 나와서 ,
정확도가 50이라고 표현할수도 있습니다.
동일한 정확도이지만 k-100일 경우가 분산이 더 높은 결과임은 틀림없습니다.)
How to measure the model’s bias-variance?
After k-fold cross validation, we’ll get k different model estimation errors (e1, e2 …..ek). In ideal scenario, these error values should add to zero. To return the model’s bias, we take the average of all the errors. Lower the average value, better the model.
Similarly for calculating model’ variance, we take standard deviation of all errors. Lower value of standard deviation suggests our model does not vary a lot with different subset of training data.
We should focus on achieving a balance between bias and variance. This can be done by reducing the variance and controlling bias to an extent. It’ll result in better predictive model. This trade-off usually leads to building less complex predictive models.
그렇다면 실습을 해볼 필요가 있습니다.
R 프로그래밍 예제
#C 드라이브에 RData폴더를 만들고 아래 명령어를 치게되면 working directory 가 Rdata로 지정됩니다. 폴더가 없으면 error나므로 일단 앞에 #을 붙여서 주석처리를 하였습니다.
#setwd('C:/RData')
#붓꽃데이터를 활용한 분석을 합니다. 데이터셋은 유명한 iris데이터 셋으로 진행할 것이며, 워낙 유명해서 보통 library에 내장되어 있습니다.
#iris데이터는 총 5개의 열로 이루어져 있고, 150행이 존재합니다.
#처음 4개의 열은 Sepal length(꽃받침 세로길이), Sepal width(꽃받침의 가로길이), Petal length(꽃입의 세로길이), Petal width(꽃입의 가로 길이)가 들어 있으며, 마지막열은 그 붓꽃의 종류를 적어놓고 종류는 , setosa, versicolor, virginica 이렇게 3종류로 되어 있습니다.
#모델링에 이용될 알고리즘은 rf즉 Random forest 알고리즘을 이용하였습니다.
#랜덤 포레스트 알고리즘을 이용해서 꽃받침 가로길이, 꽃입 세로길이, 꽃입 가로길이를 입력했을때, sepal.length 즉 꽃받침의 길이을 예측하고 그 결과를 검증하는 프로그램입니다.
install.packages("plyr")
install.packages("dplyr")
install.packages("randomForest")
#아래 라이브러리 가져오는 명령어들이 error날경우 위를 실행하세요.
#시작은 여기서부터
library(plyr)
library(dplyr)
library(randomForest)
data <- iris
#그 유명한 iris data set을 가지고 오기때문에 단순한 명령어가 가능합니다.
glimpse(data)
#데이터 확인해보는 명령어
#cross validation, using rf to predict sepal.length
k = 5
data$id <- sample(1:k, nrow(data), replace = TRUE)
list <- 1:k
# prediction and test set data frames that we add to with each iteration over
# the folds
prediction <- data.frame()
testsetCopy <- data.frame()
#데이터 프레임 초기화
#아래는 쓸데 없지만 그냥 멋있음을 위해 존재
#Creating a progress bar to know the status of CV
progress.bar <- create_progress_bar("text")
progress.bar$init(k)
#|================================================================================================================| 100%
#progress bar는 위의 모양같이 생겼고 굳이 넣을 필요없는데 비쥬얼을 위해서 넣음
#function for k fold
#i는 1부터 5로 나눈후에 5번을 진행하도록 합니다.
for(i in 1:k){
# remove rows with id i from dataframe to create training set
# select rows with id i to create test set
trainingset <- subset(data, id %in% list[-i])
testset <- subset(data, id %in% c(i))
#데이터를 5등분하고 한번 뽑은 test data가 다시 train 으로 가지 않도록 5등분 합니다.
#run a random forest model
mymodel <- randomForest(trainingset$Sepal.Length ~ ., data = trainingset, ntree = 100)
#랜덤 포레스트 알고리즘으로 꽃받침의 길이를 나머지 데이터로 예측하는 모델을 만듭니다.
#remove response column 1, Sepal.Length
temp <- as.data.frame(predict(mymodel, testset[,-1]))
# append this iteration's predictions to the end of the prediction data frame
prediction <- rbind(prediction, temp)
# append this iteration's test set to the test set copy data frame
# keep only the Sepal Length Column
testsetCopy <- rbind(testsetCopy, as.data.frame(testset[,1]))
progress.bar$step()
}
# add predictions and actual Sepal Length values
result <- cbind(prediction, testsetCopy[, 1])
names(result) <- c("Predicted", "Actual")
result$Difference <- abs(result$Actual - result$Predicted)
# As an example use Mean Absolute Error as Evalution
summary(result$Difference)
감사합니다.
'라이언의 빅데이터 강좌' 카테고리의 다른 글
| 004 데이터분석 시작전 검정 방법 선택 전략 (첫번째) (0) | 2017.04.16 |
|---|---|
| 003 t-검정과 가설 검증 (2) | 2017.04.16 |
| 002 선형회귀 및 Polynomial regression 고찰 with Python (1) | 2017.02.05 |
| 빅데이터 강좌의 커리큘럼 (3) | 2017.01.22 |
| 빅데이터를 전공하지 않은 비전공자를 위한 강의를 만들어볼까 합니다. (3) | 2017.01.22 |